How It's Built: Open Interpreter
Open Interpreter (OI) is an open source project allowing Large Language Models to execute code on your laptop. It’s generated some buzz with its impressive demos.
Personally, I’m interested in understanding the prompt architectures that projects are building around LLMs. For me, this part of the generative AI wave is under-explored, and I think will ultimately lead to a catalog of problem solving patterns, akin to The Great Mental Model project or Design Patterns.
So the goal of this post isn’t to explain how to use OI. Instead I’m going to explore the architecture of Open Interpreter and how it’s built.
Open Interpreter Architecture
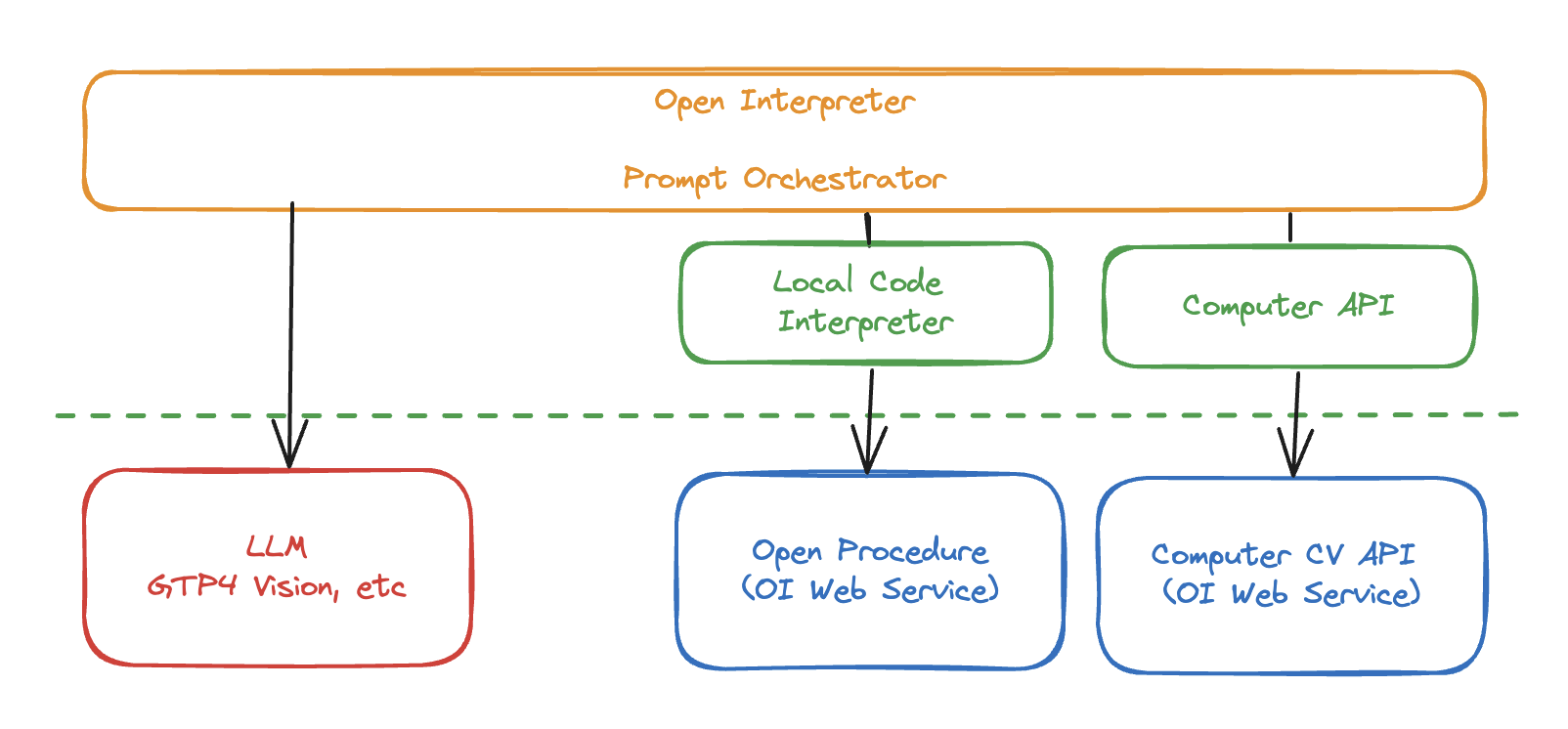
Keep in mind that this is a rapidly evolving project so my description represents a snapshot in time (Feb 2024). Currently, Open Interpreter has two main components: a local code interpreter and “OS Mode”.
The local code interpreter is similar to OpenAI’s existing code interpreter except that it allows execution of various programming languages on your own environment, like the laptop you’re running on.
OS Mode builds on that, introducing a python-based Computer API lets the LLM run commands to control their desktop. This includes things like taking screenshots, reading the screen, and clicking on things.
These two components are powered by an LLM, but the OI package also calls out to two other OI web services (when not running in offline mode): A RAG service for loading code snippet hints and a computer vision service. As a result, unless you’re offline, it’s worth calling out that you’re sending a lot of data to Open Interpreter’s servers too.
Local Interpreter
This is where the project started in September last year. It’s a way to run code on your local machine. It’s a collection of language adapters that can run code locally and return the result. This is extensible (add your own language support) and overridable as well. For example, you can modify the python adapter to run code in a hosted environment like E2B. Fly.io’s FLAME pattern would fit nicely here. It provides some security out of the box, like requiring user to confirm code execution beforehand, but you can absolutely footgun yourself.
OI talks about extending OpenAI’s message syntax to include a “computer” new role and types. It’s worth noting this syntax is only used when talking to OI. OpenAI isn’t aware of the new messages. To figure out which code to execute, OI looks for markdown code blocks or uses function calling if enabled.
This is also where the code hints RAG service called Open Procedures is used. It’s running on Replit at https://open-procedures.replit.app. Though the service describes itself returning code snippets, really it’s more recipes and hints for common pitfalls such as importing the correct libraries to read PDFs.
It’s an interesting use of RAG; a way to dynamically load hints on correct techniques. At the moment though, it doesn’t seem that useful. In my experimentation, it’s suffering from the common RAG failure mode of stuffing the prompt with a irrelevant information. For example, if you run the curl example about reversing a string, you’ll get an irrelevant response about summarizing text. It’s likely most useful as a targeted way to “monkey patch” fixes in common requests.
OS Mode
This is the newest addition to the project. It introduces a python API that allows the LLM to orchestrate the host machine with API calls like computer.display.view() which takes a screenshot and sends it to the model and computer.mouse.click("some onscreen text"). This is most interesting because it relies on computer vision to read the screen in plain text. It’s effectively a Naive/Plain Text API for the screen. And this is also where some of the crazier demos come from. The LLM can now use the python API to manipulate a computer, open a separate IDE, and run code in that IDE. The Arduino demo is the most compelling example of this I’ve seen.
This is also where the second Open Interpreter web service comes in https://api.openinterpreter.com. If you’re offline, OI will stead use OpenCV to read the screen and it’s not clear what if anything the hosted version does differently at this point, though there’s a comment in source code about local being slow.
Prompt Architecture
The system prompt wraps these two things together. It sets the stage: “You are a world-class programmer that can complete any goal by executing code.” It automatically includes a “[User Info]” section about the user’s environment and a “[Recommended Procedures]” section with everything returned from the Open Procedures RAG service.
OI tweaks how the prompt is structured based on the models passed in. If OS mode is enabled, the prompt includes a breakdown of the computer API calls including hints on which to rely on, as well as a detailed instruction manual of how to use the API and even analyze screenshots.
The whole thing is then run in a chain-of-thought loop where the model is asked to complete the prompt, the code is executed, the results analyzed, and then given back to the model to continue. One of the optional flags is --force_task_completion and it’s interesting to see how the prompt is adjusted to force the model to continue or explicitly give up.
The result is a service that can make long chains of actions and decisions, theoretically debugging its own issues in order to accomplish the initial user prompt.
It’s also worth calling out that, though OI designed for GPT 4 in mind, it can be used with a wide variety of LLMs including locally hosted models. This is thanks to a separate project called LiteLLM which provides wrapper around many LLMs making them all use OpenAI’s Completion API as a common interface. It turns out LiteLLM also provides an LLM proxy which lets you log messages and responses. I used this to see messages going back and forth.
Takeaways
When I started digging into Open Interpreter, I had no mental model of where the “smarts lived”. I would have naively assumed that GPT 4 was required and was doing all the work. Now it’s much easier to see the clever division of labor that allows it to run on a wide variety of models and environments.
For me:
-
I knew chain-of-thought was a powerful technique, but the idea of giving the model a simple python API it can control seems to be extensible for anything. I think you could do this without actually needing the code interpreter and simply parsing the series of commands.
-
I was surprised to find the two OI web services. On one hand, they’re interesting ways to combine multiple ML techniques together to assist the model. On the other hand, they’re not providing a ton of value yet and I suspect this is likely a longterm monetization hook.
-
I didn’t spend much time actually trying to build with OI and so that’s the next step for me. I’m curious to see how the model behaves in practice with real world problems. I’m also wondering if the approach could be applied to other problems beyond writing code.
This was a really interesting project to dig into and I’m excited to see where it goes. I’d also love any suggestions for other projects that would be similarly interesting. We’re still early days in understanding how to build around LLMs and I think there’s a lot of interesting work to be done.