How Does GPT "Know"?
Everyone I read these days is in the middle of a series of posts exploring the capabilities of Large Language Models (LLMs). It’s fascinating to see the global community trying to build a collective understanding of how they work and their potential impacts, and I’m along for the ride. Expect this to be the first of a series of posts as a I rubber duck all this out for myself.
To start, I’ve been exploring how GPT “knows” what it knows, with the intention of helping it know more things in the future. It’s not a straight forward answer and it also appears to be widely misunderstood. It’s easy to think of it as Google Search 2.0, trained on the world’s knowledge and having an instant reference to everything. It’s common for people to think it learns and recalls every single conversation it has. These assumptions aren’t quite right, in ways that matter for how we can work with LLMs. So let’s take a look at how they actually work.
I use LLMs, models, AI, GPT and ChatGPT interchangeably here to refer to the same class of Generative machine learning techniques and the resulting emergent behaviors. For this high-level discussion, differences between them don’t matter much.
After writing, I realized I started to refer to these models as “they” and I have conflicted feelings about that. I’ve left that here.
The LLM Knowledge Hierarchy
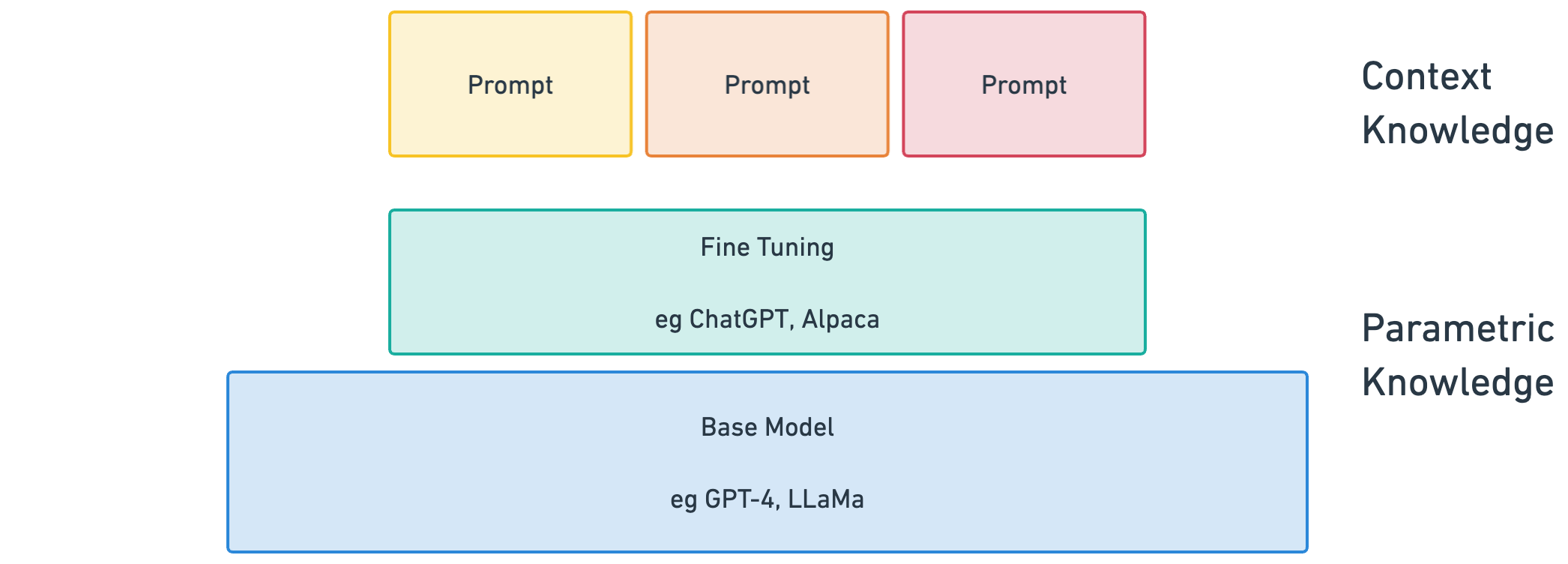
You can imagine the knowledge of an LLM as existing in three tiers.
-
Base Model - Think of this as less “knowledge” and more “intuition”.
-
Fine Tuning - Think of this as “on the job training”.
-
Prompting - Think of this as an individual task or project on the job.
The first two are both forms of parametric knowledge, meaning knowledge that’s encoded in the parameters that make up the model. The third is context knowledge, knowledge available only within the specific context. The differences will become apparent as we dig into them.
The Base Model
Here’s the extremely quick summary on what LLMs are (and if you’d like to go deep, Wolfram’s essay is a great place to start):
LLMs build on the neural network approach that has become dominate machine learning technique over the last decade. The network itself is made out of a billions of bits of logic called parameters that are interconnected by simple math that adjusts their connections based on weights. In constructing the network, they use a newer pattern called a transformer to train a model to do a very simple task: given some initial text, predict the next character or word. GPT and comparable LLMs actually predict tokens which is best thought of as a word part. A few companies such as OpenAI, Anthropic, and Hugging Face realized that the resulting models started producing remarkable results simply if they were large enough, where large refers to the number of parameters in their model; this is actually where the “large” in large language models comes from. And since discovering that, OpenAI amongst others have been throwing as much compute as they can to scale up their models.
As a result, you almost certainly won’t be building one of these yourself (though, if you’re motivated, you can actually run one of these on your laptop thanks to Facebook Research’s LLaMa project and the people who leaked their work). But companies like OpenAI have made their base models GPT-3, 3.5, and 4 available to use. So let’s take a look at what they’re capable of with an analogy:
In the world of hiring, a manager want to hire a “generalist”. Generalists are candidates that thought to be very smart and adaptive. They may not have a ton of experience, but they can work on anything because they’re smart enough to just figure it out and pick it up along the way.
A good base model is the ultimate generalist. It’s very flexible and could work on a bunch of different things, if only it understood how. In fact, one of the ways that models are evaluated is how “generalizable” they are, meaning how easy it is to apply them to work on other problems beyond the ones they were trained on.
One important point to highlight though is that base models shouldn’t be thought of a big database. Sam Altman, founder of OpenAI calls them “Reasoning Machines”. Though the LLMs making headlines today are trained on a significant percentage of the written content of humanity, they’re not a giant index of records like Google is. An LLM is not storing copies of every blog post it reads. It’s remembering the patterns of the text in its weights and then eventually using those weights to probabilistically (meaning with some randomness) generate the next series of tokens that would follow. It turns out that with a sufficiently large enough number of parameters, a behavior that looks an awful lot like reasoning starts to emerge.
So when you’re asking a base model to recommend a great soba restaurant in Seattle, it generates a series of next words that may spell out a good choice from its intuition. In fact, more often than not, you’ll get very compelling responses. But it may also end up just making something up that sounds plausible, which we’ve now started calling hallucinations.
Humans are guilty of this too of course. We’ve all answered a friend’s question confidently only to have them say “Are you sure?” and then you suddenly don’t know. You have to think hard to remember. And that act of thinking hard to remember is accessing a different part of our brain to pull the series of events. Keep this idea of a multi-tiered brain architecture in mind, because that’s effectively what we’re exploring in this space.
The important thing to take away is that a base model is a generalist with the raw horse power to reason and the intuition to build up sentences following on some initial text. And that’s it, nothing more. To get all the magical conversation we see in ChatGPT, there’s more to do.
Fine Tuning
To improve the performance of a base model on a particular task, the next step is fine tuning. Think of this as the on-the-job training for the generalist base model. This process takes a more narrowly defined set of training data for a specific task and examples of great responses, and runs the model through them. In this case though, the weights in the model are adjusted more aggressively to steer the model to the desired type of results. You’re effectively turning the generalist into a specialist.
The job to be done here is entirely up to the fine-tuner to decide. You could fine tune specifically to create travel itineraries or generate lyrics for pop song bangers if you wanted to. OpenAI chose to fine tune for “instruction following” as the job to be done in order to create InstructGPT, ChatGPT’s predecessor.
It turns out that instruction following is a particularly flexible pattern to accomplish a bunch of different things, just as predicting the next token, or the transformer pattern before that. Though LLMs often feel like magic, a surprising amount of it is built on the discovery of these relatively simple and intuitive building blocks that have outsized results. And part of the reason this space feels like it’s moving so fast is the compounding effects of applying and discovering more of these types of generic building blocks.
Now fine tuning still requires a lot of specific data, in addition to also needing more compute, though dramatically less than training the base model. You might be able to cleverly construct them from existing datasets, or you may just need to ask humans to create the data for you. Reinforcement Learning from Human Feedback (RLHF) is specifically credited with making ChatGPT the breakout success it is and when AI news talks about Google forcing all of its employees to talk to Bard, this is what they’re doing. That means fine tuning can also be expensive and time consuming, in addition to the compute. But if you’re really clever, you can just have the AI talk to the AI, which is exactly what Stanford did with Alpaca. They used ChatGPT to generate examples of good questions and responses to train Facebook’s LLaMa (which means you can also run the fine tuned Alpaca on a laptop).
Fine Tuning is ultimately the difference between GPT 3/4 and ChatGPT. The former is general, and the latter is fine tuned including with RLHF. And Fine Tuning itself is a spectrum. You can take the ChatGPT model that OpenAI has fine tuned for instruction following and further fine tune that to write cold out reach sales emails like so many YC startups these days.
But as you use fine tuning to specialize, the model becomes less and less of a generalist. As a friend put it, as you fine-tune toward a specific outcome, you are tuning away from everything else. Too much tuning and you run the risk of overfitting where the model becomes too specifically good at answering the questions it was trained on, and completely loses its ability to perform on questions it hasn’t seen before.
Overfitting may turn out to be a tragically poetic term for some of the impacts of AI on the wider workforce as this wave continues. Technologists often talk about the coming disruption and the intention to retrain millions of people that will be affected. But it’s easy to see that many of those people are specialists overfit to their current roles and careers, and they may not be ready to become generalists again.
Ultimately, fine tuning is still working with parametric knowledge, tuning the parameters of the model for specific outcomes, and it’s also a time and compute heavy process. But with instruction following LLMs, there’s another way to give them knowledge, at least in the specific moment.
Prompting
In the world of machine learning, when model is given inputs and asked to generate an output, that act is called an inference. Specifically working with an LLM trained to generate more text, the input is called the prompt and its response is called a continuation. The prompt is just the piece of text the LLM is asked to continue from.
So far, we’ve given our generalist base model the on-the-job training to do the work of responding to requests. In this framing, you can think of the prompt now as the project it has to work on.
Writing good prompts–now called prompt engineering–has become the new hot role in AI. One of the reasons is that this is where the compute and time involved with generating a useful output is finally cheap enough to easily experiment. This also happens to be the place where specific knowledge can be easily loaded without the cost of of training. As a result, a surprising amount of the AI-based product innovation happening right now is actually just happening in the prompt, rather than the training. So much so that it’s worth talking about about a few of the different techniques on their own in more detail, which has spawned a separate second article.
One thing to note through is that, at least right now, LLMs do not learn from prompting (at least directly). They don’t immediately store the conversations they have with you and reference that knowledge with others. Machine learning refers to the difference between online and offline training, with online training adjusting the model’s parameters after each inference while offline purely training separately from inference. GPT-Ns today are offline trained. Perhaps for compute costs or quality reasons, but either way, your conversation with ChatGPT does not change the the underlying model. At least, not immediately. OpenAI retains the right to train on the chat logs of conversations ChatGPT has and they almost certainly do. But they state they will not do the training with any conversations happening over the API, and if you trust their word, that means the conversation will never influence the GPT’s parametric knowledge.
Instead, the conversation you have with ChatGPT is only context knowledge. In fact, the full “chat history” back and forth is fed back to the model as an extended part of the prompt every time you ask a follow up. You can think of your full conversation as being a single expanding prompt. This is effectively the short term memory of ChatGPT. You actually see this in action if you’re using ChatGPT’s API. There, it’s your responsibility to keep sending back the whole conversation each time. If you don’t, ChatGPT is just starting each response from scratch every time, wiping it’s memory.
And as that history extends, it can become an overwhelming amount of context to digest. That’s why it can get a little slow and confused with longer conversations and why these chat-based UIs prominently feature a “clear conversation history” button.
One interesting idea is that you could imagine implementing “conversation compression” by asking GPT separately to keep iteratively summarizing the details of the past conversation to just salient details.
The important idea here is that prompt represents all the context that the LLM can proceed from, and that context can include a lot more information beyond just your current pressing question. Most of the AI products being built today are actually building prompts rather than training models.
Just The Start
Hopefully this gives you an overview of how the generalist Base Model can be fine tuned into specializing on more specific approaches such as instruction following, and then given projects to work with through prompts.
But, this is a very high level summary and it’s become obvious that much of the innovation in helping LLMs know more today actually revolves entirely around the process of designing prompts. So follow me as we go dive into the techniques that various companies and projects are using to structure prompts in the next post.